Introduction to C++
C++, as we all know is an extension to C language and was developed by Bjarne Stroustrup at bell labs. C++ is an intermediate-level language, as it comprises a confirmation of both high level and low-level language features. C++ is a statically typed, free form, multiparadigm, compiled general-purpose language.
C++ is an Object Oriented Programming language but is not purely Object Oriented. Its features like Friend and Virtual, violate some of the very important OOPS features, rendering this language unworthy of being called completely Object Oriented. Its a middle-level language.
Benefits of C++ over C Language
The major difference being OOPS concept, C++ is an object-oriented language whereas C language is a procedural language. Apart from this, there are many other features of C++ which give this language an upper hand on C language.
Following features of C++ makes it a stronger language than C,
1. There is Stronger Type Checking in C++.
2. All the OOPS features in C++ like Abstraction, Encapsulation, Inheritance, etc makes it more worthy and useful for programmers.
3. C++ supports and allows user-defined operators (i.e Operator Overloading) and function overloading is also supported in it.
4. Exception Handling is there in C++.
5. The Concept of Virtual functions and also Constructors and Destructors for Objects.
6. Inline Functions in C++ instead of Macros in C language. Inline functions make complete function bodies act like Macro, safely.
7. Variables can be declared anywhere in the program in C++ but must be declared before they are used.
C++ adn OOP
Object Oriented Programming is a programming style that is associated with the concept of Class, Objects, and various other concepts revolving around these two, like Inheritance, Polymorphism, Abstraction, Encapsulation, etc.
Let us try to understand a little about all these, through a simple example. Human Beings are living forms, broadly categorized into two types, Male and Female. Right? It's true. Every Human being(Male or Female) has two legs, two hands, two eyes, one nose, one heart, etc. There are body parts that are common for Male and Female, but then there are some specific body parts, present in a Male which are not present in a Female, and some body parts present in Females but not in Males.
All Human Beings walk, eat, see, talk, hear etc. Now again, both Male and Female, performs some common functions, but there are some specifics to both, which is not valid for the other.
For example:
A Female can give birth, while a Male cannot, so this is only for the Female.
Human Anatomy is interesting, isn't it? But let's see how all this is related to C++ and OOPS. Here we will try to explain all the OOPS concepts through this example and later we will have the technical definitions for all this.
Class
Here we can take Human Being as a class. A class is a blueprint for any functional entity which defines its properties and its functions. Like Human Being, having body parts, and performing various actions.
Inheritance
Considering HumanBeing a class, which has properties like hands, legs, eyes etc, and functions like walk, talk, eat, see etc. Male and Female are also classes, but most of the properties and functions are included in HumanBeing, hence they can inherit everything from class HumanBeing using the concept of Inheritance.
Objects
My name is Abhishek, and I am an instance/object of class Male. When we say, Human Being, Male or Female, we just mean a kind, you, your friend, me we are the forms of these classes. We have a physical existence while a class is just a logical definition. We are the objects.
Abstraction
Abstraction means, showcasing only the required things to the outside worked while hiding the details. Continuing our example, Human Being's can talk, walk, hear, eat, but the details are hidden from the outside world. We can take our skin as the Abstraction factor in our case, hiding the inside mechanism.
Encapsulation
This concept is a little tricky to explain with our example. Our Legs are binded to help us walk. Our hands, help us hold things. This binding of the properties to functions is called Encapsulation.
Polymorphism
Polymorphism is a concept, which allows us to redefine the way something works, by either changing how it is done or by changing the parts using which it is done. Both the ways have different terms for them.
If we walk using our hands, and not legs, here we will change the parts used to perform something. Hence this is called Overloading.
And if there is a defined way of walking, but I wish to walk differently, but using my legs, like everyone else. Then I can walk like I want, this will be calles as Overriding.
OOPS Concept Definitions
Now, let us discuss some of the main features of Object-Oriented Programming which you will be using in C++(technically).
1. Objects
2. Classes
3. Abstraction
4. Encapsulation
5. Inheritance
6. Overloading
7. Exception Handling
Objects
Objects are the basic unit of OOP. They are instances of class, which have data members and uses various member functions to perform tasks.
Class
It is similar to structures in C language. Class can also be defined as user defined data type but it also contains functions in it. So, class is basically a blueprint for object. It declare & defines what data variables the object will have and what operations can be performed on the class's object.
Abstraction
Abstraction refers to showing only the essential features of the application and hiding the details. In C++, classes provide methods to the outside world to access & use the data variables, but the variables are hidden from direct access. This can be done to access specifiers.
Encapsulation
It can also be said data binding. Encapsulation is all about binding the data variables and functions together in class.
Inheritance
Inheritance is a way to reuse once written code again and again. The class which is inherited is called base calls & the class which inherits is called derived class. So when a derived class inherits a base class, the derived class can use all the functions which are defined in a base class, hence making code reusable.
Polymorphism
It is a feature, which lets us create functions with the same name but different arguments, which will perform differently. That is functions with the same name, functioning in a different ways. Or, it also allows us to redefine a function to provide its new definition. You will learn how to do this in detail soon in the coming lessons.
Exception Handling
Exception handling is a feature of OOP, to handle unresolved exceptions or errors produced at runtime.
Basics of C++
In this section we will cover the basics of C++, it will include the syntax, variable, operators, loop types, pointers, references and information about other requirements of a C++ program. You will come across lot of terms that you have already studied in C language.
Syntax and Structure of C++ program
Here we will discuss one simple and basic C++ program to print "Hello this is C++" and its structure in parts with details and uses.
First C++ program
include <iostream>
using namespace std;
int main()
{
cout << "Hello this is C++";
}
Header files are included at the beginning just like in C program. Here iostream is a header file which provides us with input & output streams. Header files contained predeclared function libraries, which can be used by users for their ease.
Using namespace std, tells the compiler to use standard namespace. Namespace collects identifiers used for class, object and variables. NameSpace can be used by two ways in a program, either by the use ofusing statement at the beginning, like we did in above mentioned program or by using name of namespace as prefix before the identifier with scope resolution (::) operator.
Example : std::cout << "A";
main(), is the function which holds the executing part of program its return type is int.
cout <<, is used to print anything on screen, same as printf in C language. cin and cout are same asscanf and printf, only difference is that you do not need to mention format specifiers like, %d for int etc, in cout & cin.
Comments
For single line comments, use // before mentioning comment, like
cout<<"single line"; // This is single line comment
For multiple line comment, enclose the comment between /* and */
/*this is
a multiple line
comment */
Using Classes
Classes name must start with capital letter, and they contain data variables and member functions. This is a mere introduction to classes, we will discuss classes in detail throughout the C++ tutorial.
class Abc
{
int i; //data variable
void display() //Member Function
{
cout<<"Inside Member Function";
}
}; // Class ends here
int main()
{
Abc obj; // Creatig Abc class's object
obj.display(); //Calling member function using class object
}
This is how class is defined, its object is created and the member functions are used.
Variables can be declared anywhere in the entire program but must be declared before they are used. Hence, we don't need to declare variable at the start of the program.
Data Types in C++
They are used to define type of variables and contents used. Data types define the way you use storage in the programs you write. Data types can be built in or abstract.
Built in Data Types
These are the data types that are predefined and are wired directly into the compiler. eg: int, char, etc.
User defined or Abstract data types
These are the type, that user creates as a class. In C++ these are classes where as in C it was implemented by structures.
Basic Built in types
|
|
for character storage ( 1 byte ) |
|
|
for integral number ( 2 bytes ) |
|
|
single precision floating point ( 4 bytes ) |
|
|
double precision floating point numbers ( 8 bytes ) |
Example :
char a = 'A'; // character type
int a = 1; // integer type
float a = 3.14159; // floating point type
double a = 6e-4; // double type (e is for exponential)
Other Built in types
|
|
Boolean ( True or False ) |
|
|
Without any Value |
|
|
Wide Character |
Enum as Data type
Enumerated type declares a new type-name and a sequence of value containing identifiers which has values starting from 0 and incrementing by 1 every time.
For Example :
enum day(mon, tues, wed, thurs, fri) d;
Here an enumeration of days is defined with variable d. mon will hold value 0, tue will have 1 and so on. We can also explicitly assign values, like, enum day(mon, tue=7, wed);. Here, mon will be 0, tue is assigned 7, so wed will have value 8.
Modifiers
Specifiers modify the meanings of the predefined built-in data types and expand them to a much larger set. There are four data type modifiers in C++, they are :
1. long
2. short
3. signed
4. unsigned
Below mentioned are some important points you must know about the modifiers,
- long and short modify the maximum and minimum values that a data type will hold.
- A plain int must have a minimum size of short.
- Size hierarchy : short int < int < long int
- Size hierarchy for floating point numbers is : float < double < long double
- long float is not a legal type and there are no short floating point numbers.
- Signed types includes both positive and negative numbers and is the default type.
- Unsigned, numbers are always without any sign, that is always positive.
What are Variables
Variable are used in C++, where we need storage for any value, which will change in program. Variable can be declared in multiple ways each with different memory requirements and functioning. Variable is the name of memory location allocated by the compiler depending upon the datatype of the variable.
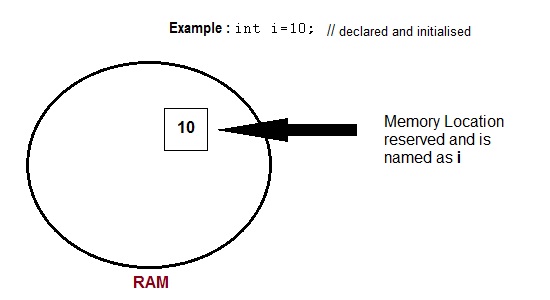
Basic types of Variables
Each variable while declaration must be given a datatype, on which the memory assigned to the variable depends. Following are the basic types of variables,
|
|
For variable to store boolean values( True or False ) |
|
|
For variables to store character types. |
|
|
for variable with integral values |
|
|
|
Declaration and Initialization
Variable must be declared before they are used. Usually, it is preferred to declare them at the starting of the program, but in C++ they can be declared in the middle of program too but must be done before using them.
Example :
int i; // declared but not initialised
char c;
int i, j, k; // Multiple declaration
Initialization means assigning value to an already declared variable,
int i; // declaration
i = 10; // initialization
Initialization and declaration can be done in one single step also,
int i=10; //initialization and declaration in same step
int i=10, j=11;
If a variable is declared and not initialized by default it will hold a garbage value. Also, if a variable is once declared and if try to declare it again, we will get a compile-time error.
int i,j;
i=10;
j=20;
int j=i+j; //compile time error, cannot redeclare a variable in same scope
Scope of Variables
All the variables have their area of functioning, and out of that boundary they don't hold their value, this boundary is called scope of the variable. For most of the cases its between the curly braces,in which variable is declared that a variable exists, not outside it. We will study the storage classes later, but as of now, we can broadly divide variables into two main types,
1. Global Variables
2. Local variables
Global variables
Global variables are those, which ar once declared and can be used throughout the lifetime of the program by any class or any function. They must be declared outside the main() function. If only declared, they can be assigned different values at different time in program lifetime. But even if they are declared and initialized at the same time outside the main() function, then also they can be assigned any value at any point in the program.
Example: Only declared, not initialized
include <iostream>
using namespace std;
int x; // Global variable declared
int main()
{
x=10; // Initialized once
cout <<"first value of x = "<< x;
x=20; // Initialized again
cout <<"Initialized again with value = "<< x;
}
Local Variables
Local variables are the variables that exist only between the curly braces, in which it declared. Outside that, they are unavailable and lead to a compile-time error.
Example :
include <iostream>
using namespace std;
int main()
{
int i=10;
if(i<20) // if condition scope starts
{
int n=100; // Local variable declared and initialized
} // if condition scope ends
cout << n; // Compile time error, n not available here
}
Some special types of variable
There are also some special keywords, to impart unique characteristics to the variables in the program. Following two are mostly used, we will discuss them in details later.
1. Final - Once initialized, its value cant be changed.
2. Static - These variables holds their value between function calls.
Example :
include <iostream>
using namespace std;
int main()
{
final int i=10;
static int y=20;
{
Operators in C++
Operators are special type of functions, that takes one or more arguments and produces a new value. For example : addition (+), substraction (-), multiplication (*) etc, are all operators. Operators are used to perform various operations on variables and constants.
Types of operators
1. Assignment Operator
2. Mathematical Operators
3. Relational Operators
4. Logical Operators
5. Bitwise Operators
6. Shift Operators
7. Unary Operators
8. Ternary Operator
9. Comma Operator
Assignment Operator ( = )
Operates '=' is used for assignment, it takes the right-hand side (called rvalue) and copy it into the left-hand side (called lvalue). Assignment operator is the only operator which can be overloaded but cannot be inherited.
Mathematical Operators
There are operators used to perform basic mathematical operations. Addition (+) , subtraction (-) , diversion (/) multiplication (*) and modulus (%) are the basic mathematical operators. Modulus operator cannot be used with floating-point numbers.
C++ and C also use a shorthand notation to perform an operation and assignment at same type. Example,
int x=10;
x += 4 // will add 4 to 10, and hence assign 14 to X.
x -= 5 // will subtract 5 from 10 and assign 5 to x.
Relational Operators
These operators establish a relationship between operands. The relational operators are : less than (<) , grater thatn (>) , less than or equal to (<=), greater than equal to (>=), equivalent (==) and not equivalent (!=).
You must notice that assignment operator is (=) and there is a relational operator, for equivalent (==). These two are different from each other, the assignment operator assigns the value to any variable, whereas equivalent operator is used to compare values, like in if-else conditions, Example
int x = 10; //assignment operator
x=5; // again assignment operator
if(x == 5) // here we have used equivalent relational operator, for comparison
{
cout <<"Successfully compared";
}
Logical Operators
The logical operators are AND (&&) and OR (||). They are used to combine two different expressions together.
If two statement are connected using AND operator, the validity of both statements will be considered, but if they are connected using OR operator, then either one of them must be valid. These operators are mostly used in loops (especially while loop) and in Decision making.
Bitwise Operators
There are used to change individual bits into a number. They work with only integral data types like char,int and long and not with floating point values.
# Bitwise AND operators &
# Bitwise OR operator |
# And bitwise XOR operator ^
# And, bitwise NOT operator ~
They can be used as shorthand notation too, & = , |= , ^= , ~= etc.
Shift Operators
Shift Operators are used to shift Bits of any variable. It is of three types,
- Left Shift Operator
<< - Right Shift Operator
>> - Unsigned Right Shift Operator
>>>
Unary Operators
These are the operators which work on only one operand. There are many unary operators, but increment++ and decrement -- operators are most used.
Other Unary Operators : address of &, dereference *, new and delete, bitwise not ~, logical not !, unary minus - and unary plus +.
Ternary Operator
The ternary if-else ? : is an operator which has three operands.
int a = 10;
a > 5 ? cout << "true" : cout << "false"
Comma Operator
This is used to separate variable names and to separate expressions. In case of expressions, the value of last expression is produced and used.
Example :
int a,b,c; // variables declaration using comma operator
a=b++, c++; // a = c++ will be done.
sizeof operator in C++
sizeOf is also an operator not a function, it is used to get information about the amount of memory allocated for data types & Objects. It can be used to get size of user defined data types too.
sizeOf operator can be used with and without parentheses. If you apply it to a variable you can use it without parentheses.
cout << sizeOf(double); //Will print size of double
int x = 2;
int i = sizeOf x;
typedef Operator
typedef is a keyword used in C++ language to assign alternative names to existing types. Its mostly used with user defined data types, when names of data types get slightly complicated. Following is the general syntax for using typedef,
typedef existing_name alias_name
Lets take an example and see how typedef actually works.
typedef unsigned long ulong;
The above statement define a term ulong for an unsigned long type. Now this ulong identifier can be used to define unsigned long type variables.
ulong i, j ;
typedef and Pointers
typedef can be used to give an alias name to pointers also. Here we have a case in which use of typedef is beneficial during pointer declaration.
In Pointers * binds to the right and not the left.
int* x, y ;
By this declaration statement, we are actually declaring x as a pointer of type int, whereas y will be declared as a plain integer.
typedef int* IntPtr ;
IntPtr x, y, z;
But if we use typedef like in above example, we can declare any number of pointers in a single statement.
Decision making in C++
Decision making is about deciding the order of execution of statements based on certain conditions or repeat a group of statements until certain specified conditions are met. C++ handles decision-making by supporting the following statements,
1. if statement
2. switch statement
3. conditional operator statement
4. goto statement
Decision making with if statement
The if statement may be implemented in different forms depending on the complexity of conditions to be tested. The different forms are,
1. Simple if statement
2. If....else statement
3. Nested if....else statement
4. else if statement
Simple if statement
The general form of a simple if statement is,
if( expression )
{
statement-inside;
}
statement-outside;
If the expression is true, then 'statement-inside' it will be executed, otherwise 'statement-inside' is skipped and only 'statement-outside' is executed.
Example :
#include< iostream.h>
int main( )
{
int x,y;
x=15;
y=13;
if (x > y )
{
cout << "x is greater than y";
}
}
Output : x is greater than y
if...else statement
The general form of a simple if...else statement is,
if( expression )
{
statement-block1;
}
else
{
statement-block2;
}
If the 'expression' is true, the 'statement-block1' is executed, else 'statement-block1' is skipped and 'statement-block2' is executed.
Example :
void main( )
{
int x,y;
x=15;
y=18;
if (x > y )
{
cout << "x is greater than y";
}
else
{
cout << "y is greater than x";
}
}
Output : y is greater than x
Nested if....else statement
The general form of a nested if...else statement is,
if( expression )
{
if( expression1 )
{
statement-block1;
}
else
{
statement-block 2;
}
}
else
{
statement-block 3;
}
if 'expression' is false the 'statement-block3' will be executed, otherwise it continues to perform the test for 'expression 1'. If the 'expression 1' is true the 'statement-block1' is executed otherwise 'statement-block2' is executed.
Example :
void main( )
{
int a,b,c;
clrscr();
cout << "enter 3 number";
cin >> a >> b >> c;
if(a > b)
{
if( a > c)
{
cout << "a is greatest";
}
else
{
cout << "c is greatest";
}
}
else
{
if( b> c)
{
cout << "b is greatest";
}
else
{
printf("c is greatest");
}
}
getch();
}
else-if ladder
The general form of else-if ladder is,
if(expression 1)
{
statement-block1;
}
else if(expression 2)
{
statement-block2;
}
else if(expression 3 )
{
statement-block3;
}
else
default-statement;
The expression is tested from the top(of the ladder) downwards. As soon as the true condition is found, the statement associated with it is executed.
Example :
void main( )
{
int a;
cout << "enter a number";
cin >> a;
if( a%5==0 && a%8==0)
{
cout << "divisible by both 5 and 8";
}
else if( a%8==0 )
{
cout << "divisible by 8";
}
else if(a%5==0)
{
cout << "divisible by 5";
}
else
{
cout << "divisible by none";
}
getch();
}
Points to Remember
1. In if statement, a single statement can be included without enclosing it into curly braces { }
2. int a = 5;
3. if(a > 4)
4. cout << "success";
No curly braces are required in the above case, but if we have more than one statement inside if condition, then we must enclose them inside curly braces.
5. == must be used for comparison in the expression of if condition, if you use = the expression will always return true, because it performs assignment not comparison.
6. Other than 0(zero), all other values are considered as true.
7. if(27)
8. cout << "hello";
9. In above example, hello will be printed.
Looping in C++
In any programming language, loops are used to execute a set of statements repeatedly until a particular condition is satisfied.
How it works
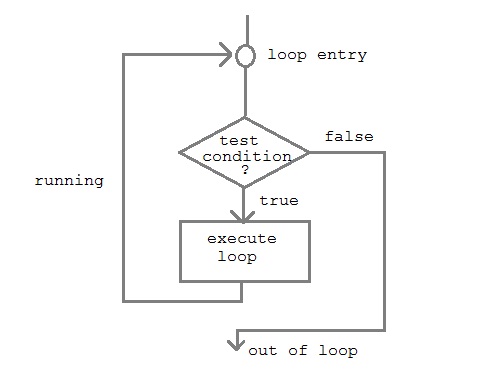
A sequence of statement is executed until a specified condition is true. This sequence of statement to be executed is kept inside the curly braces { } known as loop body. After every execution of loop body, condition is checked, and if it is found to be true the loop body is executed again. When condition check comes out to be false, the loop body will not be executed.
There are 3 type of loops in C++ language
1. while loop
2. for loop
3. do-while loop
while loop
while loop can be address as an entry control loop. It is completed in 3 steps.
- Variable initialization.( e.g int x=0; )
- condition( e.g while( x<=10) )
- Variable increment or decrement ( x++ or x-- or x=x+2 )
Syntax :
variable initialization ;
while (condition)
{
statements ;
variable increment or decrement ;
}
for loop
for loop is used to execute a set of statement repeatedly until a particular condition is satisfied. we can say it an open ended loop. General format is,
for(initialization; condition ; increment/decrement)
{
statement-block;
}
In for loop we have exactly two semicolons, one after initialization and second after condition. In this loop we can have more than one initialization or increment/decrement, separated using comma operator. for loop can have only one condition.
Nested for loop
We can also have nested for loop, i.e one for loop inside another for loop. Basic syntax is,
for(initialization; condition; increment/decrement)
{
for(initialization; condition; increment/decrement)
{
statement ;
}
}
do while loop
In some situations it is necessary to execute body of the loop before testing the condition. Such situations can be handled with the help of do-while loop. do statement evaluates the body of the loop first and at the end, the condition is checked using while statement. General format of do-while loop is,
do
{
....
.....
}
while(condition)
Jumping out of loop
Sometimes, while executing a loop, it becomes necessary to skip a part of the loop or to leave the loop as soon as certain condition becocmes true, that is jump out of loop. C language allows jumping from one statement to another within a loop as well as jumping out of the loop.
1) break statement
When break statement is encountered inside a loop, the loop is immediately exited and the program continues with the statement immediately following the loop.
2) continue statement
It causes the control to go directly to the test-condition and then continue the loop process. On encountering continue, cursor leave the current cycle of loop, and starts with the next cycle.
Storage Classes in C++
Storage classes are used to specify the lifetime and scope of variables. How storage is allocated for variables and How variable is treated by complier depends on these storage classes.
These are basically divided into 5 different types :
1. Global variables
2. Local variables
3. Register variables
4. Static variables
5. Extern variables
Global Variables
These are defined at the starting , before all function bodies and are available throughout the program.
using namespace std;
int globe; // Global variable
void func();
int main()
{
.....
}
Local variables
They are defined and are available within a particular scope. They are also called Automatic variable because they come into being when scope is entered and automatically go away when the scope ends.
The keyword auto is used, but by default all local variables are auto, so we don't have to explicitly add keyword auto before variable dedaration. Default value of such variable is garbage.
Register variables
This is also a type of local variable. This keyword is used to tell the compiler to make access to this variable as fast as possible. Variables are stored in registers to increase the access speed.
But you can never use or compute address of register variable and also , a register variable can be declared only within a block, that means, you cannot have global or static register variables.
Static Variables
Static variables are the variables which are initialized & allocated storage only once at the beginning of program execution, no matter how many times they are used and called in the program. A static variable retains its value until the end of program.
void fun()
{
static int i = 10;
i++;
cout << i;
}
int main()
{
fun(); // Output = 11
fun(); // Output = 12
fun(); // Output = 13
}
As, i is static, hence it will retain its value through function calls, and is initialized only once at the beginning.
Static specifiers are also used in classes, but that we will learn later.
Extern Variables
This keyword is used to access variable in a file which is declared & defined in some other file, that is the existence of a global variable in one file is declared using extern keyword in another file.
a
Functions in C++
A function is a group of statements that together perform a task. Every C++ program has at least one function, which is main(), and all the most trivial programs can define additional functions.
You can divide up your code into separate functions. How you divide up your code among different functions is up to you, but logically the division usually is such that each function performs a specific task.
A function declaration tells the compiler about a function's name, return type, and parameters. A function definition provides the actual body of the function.
The C++ standard library provides numerous built-in functions that your program can call. For example, function strcat() to concatenate two strings, function memcpy() to copy one memory location to another location and many more functions.
A function is known with various names like a method or a sub-routine or a procedure etc.
Defining a Function
The general form of a C++ function definition is as follows –
|
return_type function_name( parameter list ) { body of the function } |
A C++ function definition consists of a function header and a function body. Here are all the parts of a function −
- Return Type − A function may return a value. The return_type is the data type of the value the function returns. Some functions perform the desired operations without returning a value. In this case, the return_type is the keyword void.
- Function Name − This is the actual name of the function. The function name and the parameter list together constitute the function signature.
- Parameters − A parameter is like a placeholder. When a function is invoked, you pass a value to the parameter. This value is referred to as actual parameter or argument. The parameter list refers to the type, order, and number of the parameters of a function. Parameters are optional; that is, a function may contain no parameters.
- Function Body − The function body contains a collection of statements that define what the function does.
Example
Following is the source code for a function called max(). This function takes two parameters num1 and num2 and return the biggest of both –
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
|
Function Declarations
A function declaration tells the compiler about a function name and how to call the function. The actual body of the function can be defined separately.
A function declaration has the following parts –
return_type function_name( parameter list );
|
For the above defined function max(), following is the function declaration −
int max(int num1, int num2);
|
Parameter names are not important in function declaration only their type is required, so following is also valid declaration –
int max(int, int);
|
Function declaration is required when you define a function in one source file and you call that function in another file. In such case, you should declare the function at the top of the file calling the function.
Calling a Function
While creating a C++ function, you give a definition of what the function has to do. To use a function, you will have to call or invoke that function.
When a program calls a function, program control is transferred to the called function. A called function performs defined task and when it’s return statement is executed or when its function-ending closing brace is reached, it returns program control back to the main program.
To call a function, you simply need to pass the required parameters along with function name, and if function returns a value, then you can store returned value. For example −
#include <iostream>
using namespace std;
// function declaration
int max(int num1, int num2);
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int ret;
// calling a function to get max value.
ret = max(a, b);
cout << "Max value is : " << ret << endl;
return 0;
}
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
I kept max() function along with main() function and compiled the source code. While running final executable, it would produce the following result –
Max value is : 200
|
Function Arguments
If a function is to use arguments, it must declare variables that accept the values of the arguments. These variables are called the formal parameters of the function.
The formal parameters behave like other local variables inside the function and are created upon entry into the function and destroyed upon exit.
While calling a function, there are two ways that arguments can be passed to a function −
|
Sr.No |
Call Type & Description |
|
1 |
This method copies the actual value of an argument into the formal parameter of the function. In this case, changes made to the parameter inside the function have no effect on the argument. |
|
2 |
This method copies the address of an argument into the formal parameter. Inside the function, the address is used to access the actual argument used in the call. This means that changes made to the parameter affect the argument. |
|
3 |
This method copies the reference of an argument into the formal parameter. Inside the function, the reference is used to access the actual argument used in the call. This means that changes made to the parameter affect the argument. |
By default, C++ uses call by value to pass arguments. In general, this means that code within a function cannot alter the arguments used to call the function and above mentioned example while calling max() function used the same method.
Default Values for Parameters
When you define a function, you can specify a default value for each of the last parameters. This value will be used if the corresponding argument is left blank when calling to the function.
This is done by using the assignment operator and assigning values for the arguments in the function definition. If a value for that parameter is not passed when the function is called, the default given value is used, but if a value is specified, this default value is ignored and the passed value is used instead. Consider the following example −
#include <iostream>
using namespace std;
int sum(int a, int b = 20) {
int result;
result = a + b;
return (result);
}
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int result;
// calling a function to add the values.
result = sum(a, b);
cout << "Total value is :" << result << endl;
// calling a function again as follows.
result = sum(a);
cout << "Total value is :" << result << endl;
return 0;
}
When the above code is compiled and executed, it produces the following result −
Total value is :300
Total value is :120
|
Modifiers in C++
C++ allows the char, int, and double data types to have modifiers preceding them. A modifier is used to alter the meaning of the base type so that it more precisely fits the needs of various situations.
The data type modifiers are listed here −
- signed
- unsigned
- long
- short
The modifiers signed, unsigned, long, and short can be applied to integer base types. In addition, signed and unsigned can be applied to char, and long can be applied to double.
The modifiers signed and unsigned can also be used as prefix to long or short modifiers. For example, unsigned long int.
C++ allows a shorthand notation for declaring unsigned, short, or long integers. You can simply use the word unsigned, short, or long, without int. It automatically implies int. For example, the following two statements both declare unsigned integer variables.
unsigned x;
unsigned int y;
|
To understand the difference between the way signed and unsigned integer modifiers are interpreted by C++, you should run the following short program −
#include <iostream>
using namespace std;
/* This program shows the difference between
* signed and unsigned integers.
*/
int main() {
short int i; // a signed short integer
short unsigned int j; // an unsigned short integer
j = 50000;
i = j;
cout << i << " " << j;
return 0;
}
When this program is run, following is the output –
|
-15536 50000 |
The above result is because the bit pattern that represents 50,000 as a short unsigned integer is interpreted as -15,536 by a short.
Type Qualifiers in C++
The type qualifiers provide additional information about the variables they precede.
|
Sr.No |
Qualifier & Meaning |
|
1 |
const Objects of type const cannot be changed by your program during execution. |
|
2 |
volatile The modifier volatile tells the compiler that a variable's value may be changed in ways not explicitly specified by the program. |
|
3 |
restrict A pointer qualified by restrict is initially the only means by which the object it points to can be accessed. Only C99 adds a new type qualifier called restrict. |
Access Control in Classes
Now before studying how to define class and its objects, lets first quickly learn what are access specifiers.
Access specifiers in C++ class defines the access control rules. C++ has 3 new keywords introduced, namely,
1. public
2. private
3. protected
These access specifiers are used to set boundaries for availability of members of class be it data members or member functions
Access specifiers in the program, are followed by a colon. You can use either one, two or all 3 specifiers in the same class to set different boundaries for different class members. They change the boundary for all the declarations that follow them.
Public
Public, means all the class members declared under public will be available to everyone. The data members and member functions declared public can be accessed by other classes too. Hence there are chances that they might change them. So the key members must not be declared public.
class PublicAccess
{
public: // public access specifier
int x; // Data Member Declaration
void display(); // Member Function decaration
}
Private
Private keyword, means that no one can access the class members declared private outside that class. If someone tries to access the private member, they will get a compile time error. By default class variables and member functions are private.
class PrivateAccess
{
private: // private access specifier
int x; // Data Member Declaration
void display(); // Member Function decaration
}
Protected
Protected, is the last access specifier, and it is similar to private, it makes class member inaccessible outside the class. But they can be accessed by any subclass of that class. (If class A is inherited by class B, then class B is subclass of class A. We will learn this later.)
class ProtectedAccess
{
protected: // protected access specifier
int x; // Data Member Declaration
void display(); // Member Function decaration
}
Defining Class and Declaring Objects
When we define any class, we are not defining any data, we just define a structure or a blueprint, as to what the object of that class type will contain and what operations can be performed on that object.
Below is the syntax of class definition,
class ClassName
{
Access specifier:
Data members;
Member Functions(){}
};
Here is an example, we have made a simple class named Student with appropriate members,
class Student
{
public:
int rollno;
string name;
};
So its clear from the syntax and example, class definition starts with the keyword "class" followed by the class name. Then inside the curly braces comes the class body, that is data members and member functions, whose access is bounded by access specifier. A class definition ends with a semicolon, or with a list of object declarations.
Example :
class Student
{
public:
int rollno;
string name;
}A,B;
Here A and B are the objects of class Student, declared with the class definition. We can also declare objects separately, like we declare variable of primitive data types. In this case the data type is the class name, and variable is the object.
int main()
{
Student A;
Student B;
}
Both A and B will have their own copies of data members.
Accessing Data Members of Class
Accessing a data member depends solely on the access control of that data member. If its public, then the data member can be easily accessed using the direct member access (.) operator with the object of that class.
If, the data member is defined as private or protected, then we cannot access the data variables directly. Then we will have to create special public member functions to access, use or initialize the private and protected data members. These member functions are also called Accessors and Mutator methods or getter andsetter functions.
Accessing Public Data Members
Following is an example to show you how to initialize and use the public data members using the dot (.) operator and the respective object of class.
class Student
{
public:
int rollno;
string name;
};
int main()
{
Student A;
Student B;
A.rollno=1;
A.name="Adam";
B.rollno=2;
B.name="Bella";
cout <<"Name and Roll no of A is :"<< A.name << A.rollno;
cout <<"Name and Roll no of B is :"<< B.name << B.rollno;
}
Accessing Private Data Members
To access, use and initialize the private data member you need to create getter and setter functions, to get and set the value of the data member.
The setter function will set the value passed as argument to the private data member, and the getter function will return the value of the private data member to be used. Both getter and setter function must be defined public.
Example :
class Student
{
private: // private data member
int rollno;
public: // public accessor and mutator functions
int getRollno()
{
return rollno;
}
void setRollno(int i)
{
rollno=i;
}
};
int main()
{
Student A;
A.rollono=1; //Compile time error
cout<< A.rollno; //Compile time error
A.setRollno(1); //Rollno initialized to 1
cout<< A.getRollno(); //Output will be 1
}
So this is how we access and use the private data members of any class using the getter and setter methods. We will discuss this in more details later.
Accessing Protected Data Members
Protected data members, can be accessed directly using dot (.) operator inside the subclass of the current class, for non-subclass we will have to follow the steps same as to access private data member.
Member Functions in Classes
Member functions are the functions, which have their declaration inside the class definition and works on the data members of the class. The definition of member functions can be inside or outside the definition of class.
If the member function is defined inside the class definition it can be defined directly, but if it's defined outside the class, then we have to use the scope resolution :: operator along with class name along with function name.
Example :
class Cube
{
public:
int side;
int getVolume(); // Declaring function getVolume with no argument and return type int.
};
If we define the function inside class then we don't not need to declare it first, we can directly define the function.
class Cube
{
public:
int side;
int getVolume()
{
return side*side*side; //returns volume of cube
}
};
But if we plan to define the member function outside the class definition then we must declare the function inside class definition and then define it outside.
class Cube
{
public:
int side;
int getVolume();
}
int Cube :: getVolume() // defined outside class definition
{
return side*side*side;
}
The main function for both the function definition will be same. Inside main() we will create object of class, and will call the member function using dot . operator.
int main()
{
Cube C1;
C1.side=4; // setting side value
cout<< "Volume of cube C1 ="<< C1.getVolume();
}
Similarly we can define the getter and setter functions to access private data members, inside or outside the class definition.
Types of Member Functions
We already know what member functions are and what they do. Now lets study some special member functins present in the class. Following are different types of Member functions,
1. Simple functions
2. Static functions
3. Const functions
4. Inline functions
5. Friend functions
Simple Member functions
These are the basic member function, which dont have any special keyword like static etc as prefix. All the general member functions, which are of below given form, are termed as simple and basic member functions.
return_type functionName(parameter_list)
{
function body;
}
Static Member functions
Static is something that holds its position. Static is a keyword which can be used with data members as well as the member functions. We will discuss this in details later. As of now we will discuss its usage with member functions only.
A function is made static by using static keyword with function name. These functions work for the class as whole rather than for a particular object of a class.
It can be called using the object and the direct member access . operator. But, its more typical to call a static member function by itself, using class name and scope resolution :: operator.
Example :
class X
{
public:
static void f(){};
};
int main()
{
X::f(); // calling member function directly with class name
}
These functions cannot access ordinary data members and member functions, but only static data members and static member functions.
It doesn't have any "this" keyword which is the reason it cannot access ordinary members. We will study about "this" keyword later.
Const Member functions
We will study Const keyword in detail later, but as an introduction, Const keyword makes variables constant, that means once defined, there values can't be changed.
When used with member function, such member functions can never modify the object or its related data members.
//Basic Syntax of const Member Function
void fun() const {}
Inline functions
All the member functions defined inside the class definition are by default declared as Inline. We will study Inline Functions in details in the next topic.
Friend functions
Friend functions are actually not class member function. Friend functions are made to give private access to non-class functions. You can declare a global function as friend, or a member function of other class as friend.
Example :
class WithFriend
{
int i;
public:
friend void fun(); // Global function as friend
};
void fun()
{
WithFriend wf;
wf.i=10; // Access to private data member
cout << wf.i;
}
int main()
{
fun(); //Can be called directly
}
Hence, friend functions can access private data members by creating object of the class. Similarly we can also make function of other class as friend, or we can also make an entire class as friend class.
class Other
{
void fun();
};
class WithFriend
{
private:
int i;
public:
void getdata(); // Member function of class WithFriend
friend void Other::fun(); // making function of class Other as friend here
friend class Other; // making the complete class as friend
};
When we make a class as friend, all its member functions automatically become friend functions.
Friend Functions is a reason, why C++ is not called as a pure Object Oriented language. Because it violates the concept of Encapsulation.
Inline Functions in C++
All the member functions defined inside the class definition are by default declared as Inline. Let us have some background knowledge about these functions.
You must remember Preprocessors from C language. Inline functions in C++ do the same thing what Macros do in C. Preprocessors were not used in C++ because they had some drawbacks.
Drawbacks of Macro
In Macro, we define certain variable with its value at the beginning of the program, and everywhere inside the program where we use that variable, its replaced by its value on Compilation.
1) Problem with spacing
Let us see this problem using an example,
#define G (y) (y+1)
Here we have defined a Macro with name G(y), which is to be replaced by its value, that is (y+1) during compilation. But, what actually happens when we call G(y),
G(1) //Macro will replace it
the preprocessor will expand it like,
(y) (y+1) (1)
You must be thinking why this happened, this happened because of the spacing in Macro definition. Hence big functions with several expressions can never be used with macro, so Inline functions were introduced in C++.
2) Complex Argument Problem
In some cases such Macro expressions work fine for certain arguments but when we use complex arguments problems start arising.
#define MAX(x,y) x>y?1:0
Now if we use the expression,
if(MAX(a&0x0f,0x0f)) // Complex Argument
Macro will Expand to,
if( a&0x0f > 0x0f ? 1:0)
Here precedence of operators will lead to problem, because precedence of & is lower than that of >, so the macro evaluation will surprise you. This problem can be solved though using parenthesis, but still for bigger expressions problem will arise.
3) No way to access Private Members of Class
With Macros, in C++ you can never access private variables, so you will have to make those members public, which will expose the implementation.
class Y
{
int x;
public :
#define VAL(Y::x) // Its an Error
}
Inline Functions
Inline functions are actual functions, which are copied everywhere during compilation, like preprocessor macro, so the overhead of function calling is reduced. All the functions defined inside class definition are by default inline, but you can also make any non-class function inline by using keyword inline with them.
For an inline function, declaration and definition must be done together. For example,
inline void fun(int a)
{
return a++;
}
Some Important points about Inline Functions
1. We must keep inline functions small, small inline functions have better efficiency.
2. Inline functions do increase efficiency, but we should not make all the functions inline. Because if we make large functions inline, it may lead to code bloat, and might affect the speed too.
3. Hence, it is adviced to define large functions outside the class definition using scope resolution ::operator, because if we define such functions inside class definition, then they become inline automatically.
4. Inline functions are kept in the Symbol Table by the compiler, and all the call for such functions is taken care at compile time.
Access Functions
We have already studied this in topic Accessing Private Data variables inside class. We use access functions, which are inline to do so.
class Auto
{
int i;
public:
int getdata()
{
return i;
}
void setdata(int x)
{
i=x;
}
};
Here getdata() and setdata() are inline functions, and are made to access the private data members of the class Auto. getdata(), in this case is called Accessor function and setdata() is a Mutator function.
There can be overlaoded Accessor and Mutator functions too. We will study overloading functions in next topic.
Limitations of Inline Functions
1. Large Inline functions cause Cache misses and affect performance negatively.
2. Compilation overhead of copying the function body everywhere in the code on compilation, which is negligible for small programs, but it makes a difference in large code bases.
3. Also, if we require address of the function in program, compiler cannot perform inlining on such functions. Because for providing address to a function, compiler will have to allocate storage to it. But inline functions doesn't get storage, they are kept in Symbol table.
Forward References
All the inline functions are evaluated by the compiler, at the end of class declaration.
class ForwardReference
{
int i;
public:
int f() {return g()+10;} // call to undeclared function
int g() {return i;}
};
int main()
{
ForwardReference fr;
fr.f();
}
You must be thinking that this will lead to compile time error,but in this case it will work, because no inline function in a class is evaluated until the closing braces of class declaration.
Function Overloading in C++
If any class have multiple functions with same names but different parameters then they are said to be overloaded. Function overloading allows you to use the same name for different functions, to perform, either same or different functions in the same class.
Function overloading is usually used to enhance the readability of the program. If you have to perform one single operation but with different number or types of arguments, then you can simply overload the function.
Ways to overload a function
1. By changing number of Arguments.
2. By having different types of argument.
Number of Arguments different
In this type of function overloading we define two functions with same names but different number of parameters of the same type. For example, in the below mentioned program we have made two sum() functions to return sum of two and three integers.
int sum (int x, int y)
{
cout << x+y;
}
int sum(int x, int y, int z)
{
cout << x+y+z;
}
Here sum() function is overloaded, to have two and three arguments. Which sum() function will be called, depends on the number of arguments.
int main()
{
sum (10,20); // sum() with 2 parameter will be called
sum(10,20,30); //sum() with 3 parameter will be called
}
Different Datatype of Arguments
In this type of overloading we define two or more functions with same name and same number of parameters, but the type of parameter is different. For example in this program, we have two sum() function, first one gets two integer arguments and second one gets two double arguments.
int sum(int x,int y)
{
cout<< x+y;
}
double sum(double x,double y)
{
cout << x+y;
}
int main()
{
sum (10,20);
sum(10.5,20.5);
}
Default Arguments
When we mention a default value for a parameter while declaring the function, it is said to be as default argument. In this case, even if we make a call to the function without passing any value for that parameter, the function will take the default value specified.
sum(int x,int y=0)
{
cout << x+y;
}
Here we have provided a default value for y, during function definition.
int main()
{
sum(10);
sum(10,0);
sum(10,10);
}
Output : 10 10 20 First two function calls will produce the exact same value.
for the third function call, y will take 10 as value and output will become 20.
By setting default argument, we are also overloading the function. Default arguments also allow you to use the same function in different situations just like function overloading.
Rules for using Default Arguments
1. Only the last argument must be given
sum (int x,int y);
sum (int x,int y=0);
sum (int x=0,int y); // This is Incorrect
2. If you default an argument, then you will have to default all the subsequent arguments after that.
sum (int x,int y=0);
sum (int x,int y=0,int z); // This is incorrect
sum (int x,int y=10,int z=10); // Correct
3. You can give any value a default value to argument, compatible with its datatype.
Placeholder Arguments
When arguments in a function are declared without any identifier they are called placeholder arguments.
void sum (int,int);
Such arguments can also be used with default arguments.
void sum (int, int=0);
Constructors in C++
Constructors are special class functions which performs initialization of every object. The Compiler calls the Constructor whenever an object is created. Constructors iitialize values to object members after storage is allocated to the object.
class A
{
int x;
public:
A(); //Constructor
};
While defining a contructor you must remeber that the name of constructor will be same as the name of the class, and contructors never have return type.
Constructors can be defined either inside the class definition or outside class definition using class name and scope resolution :: operator.
class A
{
int i;
public:
A(); //Constructor declared
};
A::A() // Constructor definition
{
i=1;
}
Types of Constructors
Constructors are of three types :
1. Default Constructor
2. Parametrized Constructor
3. Copy COnstructor
Default Constructor
Default constructor is the constructor which doesn't take any argument. It has no parameter.
Syntax :
class_name ()
{ Constructor Definition }
Example :
class Cube
{
int side;
public:
Cube()
{
side=10;
}
};
int main()
{
Cube c;
cout << c.side;
}
Output : 10
In this case, as soon as the object is created the constructor is called which initializes its data members.
A default constructor is so important for initialization of object members, that even if we do not define a constructor explicitly, the compiler will provide a default constructor implicitly.
class Cube
{
int side;
};
int main()
{
Cube c;
cout << c.side;
}
Output : 0
In this case, default constructor provided by the compiler will be called which will initialize the object data members to default value, that will be 0 in this case.
Parameterized Constructor
These are the constructors with parameter. Using this Constructor you can provide different values to data members of different objects, by passing the appropriate values as argument.
Example :
class Cube
{
int side;
public:
Cube(int x)
{
side=x;
}
};
int main()
{
Cube c1(10);
Cube c2(20);
Cube c3(30);
cout << c1.side;
cout << c2.side;
cout << c3.side;
}
OUTPUT : 10 20 30
By using parameterized construcor in above case, we have initialized 3 objects with user defined values. We can have any number of parameters in a constructor.
Copy Constructor
These are special type of Constructors which takes an object as argument, and is used to copy values of data members of one object into other object. We will study copy constructors in detail later.
Constructor Overloading
Just like other member functions, constructors can also be overloaded. Infact when you have both default and parameterized constructors defined in your class you are having Overloaded Constructors, one with no parameter and other with parameter.
You can have any number of Constructors in a class that differ in parameter list.
class Student
{
int rollno;
string name;
public:
Student(int x)
{
rollno=x;
name="None";
}
Student(int x, string str)
{
rollno=x ;
name=str ;
}
};
int main()
{
Student A(10);
Student B(11,"Ram");
}
In above case we have defined two constructors with different parameters, hence overloading the constructors.
One more important thing, if you define any constructor explicitly, then the compiler will not provide default constructor and you will have to define it yourself.
In the above case if we write Student S; in main(), it will lead to a compile time error, because we haven't defined default constructor, and compiler will not provide its default constructor because we have defined other parameterized constructors.
Destructors
Destructor is a special class function which destroys the object as soon as the scope of object ends. The destructor is called automatically by the compiler when the object goes out of scope.
The syntax for destructor is same as that for the constructor, the class name is used for the name of destructor, with a tilde ~ sign as prefix to it.
class A
{
public:
~A();
};
Destructors will never have any arguments.
Example to see how Constructor and Destructor is called
class A
{
A()
{
cout << "Constructor called";
}
~A()
{
cout << "Destructor called";
}
};
int main()
{
A obj1; // Constructor Called
int x=1
if(x)
{
A obj2; // Constructor Called
} // Destructor Called for obj2
} // Destructor called for obj1
Single Definition for both Default and Parameterized Constructor
In this example we will use default argument to have a single definition for both defualt and parameterized constructor.
class Dual
{
int a;
public:
Dual(int x=0)
{
a=x;
}
};
int main()
{
Dual obj1;
Dual obj2(10);
}
Here, in this program, a single Constructor definition will take care for both these object initializations. We don't need separate default and parameterized constructors.
Namespace in C++
Namespace is a container for identifiers. It puts the names of its members in a distinct space so that they don't conflict with the names in other namespaces or global namespace.
Creating a Namespace
Creating a namespace is similar to creation of a class.
namespace MySpace
{
// Declarations
}
int main() {}
This will create a namespace called MySpace, inside which we can put our member declarations.
Rules to create Namespace
1. The namespace definition must be done at global scope, or nested inside another namespace.
2. Namespace definition doesn't terminates with a semicolon like in class definition.
3. You can use an alias name for your namespace name, for ease of use.
Example for Alias :
namespace StudyTonightDotCom
{
void study();
class Learn { };
}
namespace St = StudyTonightDotCom; // St is now alias for StudyTonightDotCom
4. You cannot create instance of namespace.
5. There can be unnamed namespaces too. Unnamed namespace is unique for each translation unit. They act exactly like named namespaces.
Example for Unnamed namespace :
namespace
{
class Head { };
class Tail { };
int i,j,k;
}
int main() { }
6. A namespace definition can be continued and extended over multiple files, they are not redefined or overriden.
Example :
Header1.h
namespace MySpace
{
int x;
void f();
}
Header2.h
#include "Header1.h";
namespace MySpace
{
int y;
void g();
}
Using a Namespace
There are three ways to use a namespace in program,
1. Scope Resolution
2. The using directive
3. The using declaration
With Scope Resolution
Any name (identifier) declared in a namespace can be explicitly specified using the namespace's name and the scope resolution :: operator with the identifier.
namespace MySpace
{
class A
{
static int i;
public:
void f();
};
class B; // class name declaration
void func(); //gobal function declaration
}
int MySpace::A::i=9; // Initializing static class variable
class MySpace::B
{
int x;
public:
int getdata()
{
cout << x;
}
B(); // Constructor declaration
}
MySpace::B::B() // Constructor definition
{
x=0;
}
The using directive
using keyword allows you to import an entire namespace into your program with a global scope. It can be used to import a namespace into another namespace or any program.
Namespace1.h
namespace X
{
int x;
class Check
{
int i;
};
}
Namespace2.h
include "Namespace1.h";
namespace Y
{
using namespace X;
Check obj;
int y;
}
We imported the namespace X into namespace Y, hence class Check is available in namespace Y.
Program.cpp
#include "Namespace2.h";
void test()
{
using Namespace Y;
Check obj2;
}
Hence, the using directive makes it a lot easier to use namespace, wherever you want.
The using declaration
When we use using directive, we import all the names in the namespace and they are available throughout the program, that is they have global scope.
But with using declaration, we import one specific name at a time which is available only inside the current scope.
NOTE:
Name imported with using declaration can override the name imported with using directive
Namespace.h
namespace X
{
void f() {}
void g() {}
}
namespace Y
{
void f() {}
void g() {}
}
Program.cpp
#include "Namespace.h";
void h()
{
using namespace X; // using directive
using Y::f; // using declaration
f(); // calls f() of Y namespace
X::f(); // class f() of X namespace
}
In using declaration, we never mention the argument list of a function while importing it, hence if a namespace has overloaded function, it will lead to ambiguity.
Static Keyword in C++
Static is a keyword in C++ used to give special characteristics to an element. Static elements are allocated storage only once in a program lifetime in static storage area. And they have a scope till the program lifetime. Static Keyword can be used with following,
1. Static variable in functions
2. Static Class Objects
3. Static member Variable in class
4. Static Methods in class
Static variables inside Functions
Static variables when used inside function are initialized only once, and then they hold there value even through function calls.
These static variables are stored on static storage area , not in stack.
void counter()
{
static int count=0;
cout << count++;
}
int main(0
{
for(int i=0;i<5;i++)
{
counter();
}
}
Output : 0 1 2 3 4
Let's se the same program's output without using static variable.
void counter()
{
int count=0;
cout << count++;
}
int main(0
{
for(int i=0;i<5;i++)
{
counter();
}
}
Output : 0 0 0 0 0
If we do not use static keyword, the variable count, is reinitialized everytime when counter() function is called, and gets destroyed each time when counter() functions ends. But, if we make it static, once initialized count will have a scope till the end of main() function and it will carry its value through function calls too.
If you don't initialize a static variable, they are by default initialized to zero.
Static class Objects
Static keyword works in the same way for class objects too. Objects declared static are allocated storage in static storage area, and have scope till the end of program.
Static objects are also initialized using constructors like other normal objects. Assignment to zero, on using static keyword is only for primitive datatypes, not for user defined datatypes.
class Abc
{
int i;
public:
Abc()
{
i=0;
cout << "constructor";
}
~Abc()
{
cout << "destructor";
}
};
void f()
{
static Abc obj;
}
int main()
{
int x=0;
if(x==0)
{
f();
}
cout << "END";
}
Output : constructor END destructor
You must be thinking, why was destructor not called upon the end of the scope of if condition. This is because object was static, which has scope till the program lifetime, hence destructor for this object was called when main() exits.
Static data member in class
Static data members of class are those members which are shared by all the objects. Static data member has a single piece of storage, and is not available as separate copy with each object, like other non-static data members.
Static member variables (data members) are not initialied using constructor, because these are not dependent on object initialization.
Also, it must be initialized explicitly, always outside the class. If not initialized, Linker will give error.
class X
{
static int i;
public:
X(){};
};
int X::i=1;
int main()
{
X obj;
cout << obj.i; // prints value of i
}
Once the definition for static data member is made, user cannot redefine it. Though, arithmetic operations can be performed on it.
Static Member Functions
These functions work for the class as whole rather than for a particular object of a class.
It can be called using an object and the direct member access . operator. But, its more typical to call a static member function by itself, using class name and scope resolution :: operator.
Example :
class X
{
public:
static void f(){};
};
int main()
{
X::f(); // calling member function directly with class name
}
These functions cannot access ordinary data members and member functions, but only static data members and static member functions.
It doesn't have any "this" keyword which is the reason it cannot access ordinary members. We will study about "this" keyword later.
Const Keyword
Constant is something that doesn't change. In C and C++ we use the keyword const to make program elements constant. Const keyword can be used in many context in a C++ program. Const keyword can be used with:
1. Variables
2. Pointers
3. Function arguments and return types
4. Class Data members
5. Class Member functions
6. Objects
1) Constant Variables
If you make any variable as constant, using const keyword, you cannot change its value. Also, the constant variables must be initialized while declared.
int main
{
const int i = 10;
const int j = i+10; // Works fine
i++; // This leads to Compile time error
}
In this program we have made i as constant, hence if we try to change its value, compile time error is given. Though we can use it for substitution.
2) Pointers with Const
Pointers can be made const too. When we use const with pointers, we can do it in two ways, either we can apply const to what the pointer is pointing to, or we can make the pointer itself a const.
Pointer to Const
This means that the pointer is pointing to a const variable.
const int* u;
Here, u is a pointer that points to a const int. We can also write it like,
int const* v;
still it has the same meaning. In this case also, v is a pointer to an int which is const.
Const pointer
To make the pointer const, we have to put the const keyword to the right of the *.
int x = 1;
int* const w = &x;
Here, w is a pointer, which is const, that points to an int. Now we can't change the pointer but can change the value that it points to.
NOTE : We can also have a const pointer pointing to a const variable.
const int* const x;
3) Const Function Arguments and Return types
We can make the return type or arguments of a function as const. Then we cannot change any of them.
void f(const int i)
{
i++; // Error
}
const int g()
{
return 1;
}
Some Important points to remember
1. For built in types, returning a const or non-const, doesn't make any difference.
const int h()
{
return 1;
}
it main()
{
const int j = h();
int k = h();
}
Both j and k will be assigned 1. No error will occur.
2. For user defined data types, returning const, will prevent its modification.
3. Temporary objects created while program execution are always of const type.
4. If a function has a non-const parameter, it cannot be passed a const argument while making a call.
void t(int*) { }
If we pass a const int* argument, it will give error.
5. But, a function which has a const type parameter, can be passed a const type argument as well as a non-const argument.
void g(const int*) {}
This function can have a int* as well as const int* type argument.
4) Const class Data members
These are data variables in class which are made const. They are not initialized during declaration. Their initialization occur in the constructor.
class Test
{
const int i;
public:
Test (int x)
{
i=x;
}
};
int main()
{
Test t(10);
Test s(20);
}
In this program, i is a const data member, in every object its independent copy is present, hence it is initialized with each object using constructor. Once initialized, it cannot be changed.
5) Const class Object
When an object is declared or created with const, its data members can never be changed, during object's lifetime.
Syntax :
const class_name object;
Const class Member function
A const member function never modifies data members in an object.
Syntax :
return_type function_name() const;
Example for const Object and const Member function
class X
{
int i;
public:
X(int x) // Constructor
{ i=x; }
int f() const // Constant function
{ i++; }
int g()
{ i++; }
};
int main()
{
X obj1(10); // Non const Object
const X obj2(20); // Const Object
obj1.f(); // No error
obj2.f(); // No error
cout << obj1.i << obj2.i ;
obj1.g(); // No error
obj2.g(); // Compile time error
}
Output : 10 20
Here, we can see, that const member function never changes data members of class, and it can be used with both const and non-const object. But a const object can't be used with a member function which tries to change its data members.
Mutable Keyword
Mutable keyword is used with member variables of class, which we want to change even if the object is of const type. Hence, mutable data members of a const objects can be modified.
class Z
{
int i;
mutable int j;
public:
Z()
{i=0; j=0;}
void f() const
{ i++; // Error
j++; // Works, because j is Mutable
}
};
int main(0
{
const Z obj;
obj.f();
}
References in C++
References are like constant pointers that are automatically dereferenced. It is a new name given to an existing storage. So when you are accessing the reference, you are actually accessing that storage.
int main()
{ int y=10;
int &r = y; // r is a reference to int y
cout << r;
}
Output : 10
There is no need to use the * to dereference a reference variable.
Difference between Reference and Pointer
|
References |
Pointers |
|
Reference must be initialized when it is created. |
Pointers can be initialized any time. |
|
Once initialized, we cannot reinitialize a reference. |
Pointers can be reinitialized any number of time. |
|
You can never have a NULL reference. |
Pointers can be NULL. |
|
Reference is automatically dereferenced. |
|
References in Funtions
References are generally used for function argument lists and function return values, just like pointers.
Rules for using Reference in Functions
1. When we use reference in argument list, we must keep in mind that any change to the reference inside the function will cause change to the original argument outside th function.
2. When we return a reference from a function, you should see that whatever the reference is connected to shouldn't go out of scope when fnction ends. Either make that global or static
Example to explain use of References
int* first (int* x)
{ (*x++);
return x; // SAFE, x is outside this scope
}
int& second (int& x)
{ x++;
return x; // SAFE, x is outside this scope
}
int& third ()
{ int q;
return q; // ERROR, scope of q ends here
}
int& fourth ()
{ static int x;
return x; // SAFE, x is static, hence lives till the end.
}
int main()
{
int a=0;
first(&a); // UGLY and explicit
second(a); // CLEAN and hidden
}
We have four different functions in the above program.
- first() takes a pointer as argument and returns a pointer, it will work fine. The returning pointer points to variable declared outside first(), hence it will be valid even after the first() ends.
- Similarly, second() will also work fine. The returning reference is connected to valid storage, that isint a in this case.
- But in case of third(), we declare a variable q inside the function and try to return a reference connected to it. But as soon as function third() ends, the local variable q is destroyed, hence nothing is returned.
- To remedify above problem, we make x as static in function fourth(), giving it a lifetime till main() ends, hence now a reference connected to x will be valid when returned.
Const Reference
Const reference is used in function arguments to prevent the function from changing the argument.
void g(const int& x)
{ x++; } // ERROR
int main()
{
int i=10;
g(i);
}
We cannot change the argument in the function because it is passed as const reference.
Argument Passing Guidelines
Usually call by value is used during funtcion call just to save our object or variable from being changed or modified, but whenever we pass an argument by value, its new copy is created. If we pass an object as argument then a copy of that object is created (constructor and destructors called), which affects efficiency.
Hence, we must use const reference type arguments. When we use, const reference, only an address is passed on stack, which is used inside the function and the function cannot change our argument because it is of const type.
So using const reference type argument reduces overhead and also saves our argument from being changed.
Copy Constructor in C++
Copy Constructor is a type of constructor which is used to create a copy of an already existing object of a class type.
It is usually of the form X (X&), where X is the class name. The compiler provides a default Copy Constructor to all the classes.
Syntax of Copy Constructor
class-name (class-name &)
{
. . . .
}
class MyClass{
public:
int id;
char name[20];
};
Void main(){
MyClass obj;
Obj.id = 20;
Obj.name = “Mohan”;
MyClass obj2(obj);
Cout<<obj2.id<<endl;//20
}
As it is used to create an object, hence it is called a constructor. And, it creates a new object, which is exact copy of the existing copy, hence it is called copy constructor.
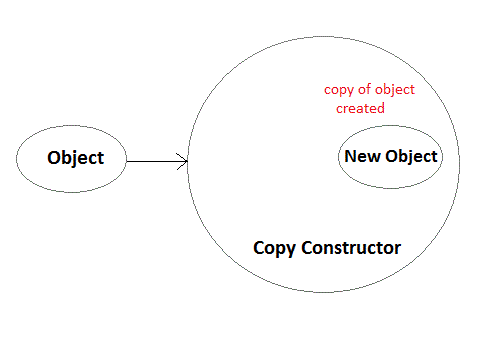
Pointers to class members
Just like pointers to normal variables and functions, we can have pointers to class member functions and member variables.
Defining a pointer of class type
We can define pointer of class type, which can be used to point to class objects.
class Simple
{
public:
int a;
};
int main()
{
Simple obj;
Simple* ptr; // Pointer of class type
ptr = &obj;
cout<<obj.a;
cout<<ptr->a; // Accessing member with pointer
}
Here you can see that we have declared a pointer of class type which points to class's object. We can access data members and member functions using pointer name with arrow -> symbol.
Pointer to Data Members of class
We can use pointer to point to class's data members (Member variables).
Syntax for Declaration :
datatypeclass_name :: *pointer_name ;
Syntax for Assignment :
pointer_name = &class_name :: datamember_name ;
Both declaration and assignment can be done in a single statement too.
datatypeclass_name::*pointer_name = &class_name::datamember_name ;
Using with Objects
For accessing normal data members we use the dot . operator with object and -> qith pointer to object. But when we have a pointer to data member, we have to dereference that pointer to get what its pointing to, hence it becomes,
Object.*pointerToMember
and with pointer to object, it can be accessed by writing,
ObjectPointer->*pointerToMember
Lets take an example, to understand the complete concept.
class Data
{
public:
int a;
void print() { cout<< "a is="<< a; }
};
int main()
{
Data d, *dp;
dp = &d; // pointer to object
int Data::*ptr=&Data::a; // pointer to data member 'a'
d.*ptr=10;
d.print();
dp->*ptr=20;
dp->print();
}
Output : a is=10 a is=20
The syntax is very tough, hence they are only used under special circumstances.
Pointer to Member Functions
Pointers can be used to point to class's Member functions.
Syntax :
return_type (class_name::*ptr_name) (argument_type) = &class_name::function_name ;
Below is an example to show how we use ppointer to member functions.
class Data
{ public:
int f (float) { return 1; }
};
int (Data::*fp1) (float) = &Data::f; // Declaration and assignment
int (Data::*fp2) (float); // Only Declaration
int main(0
{
fp2 = &Data::f; // Assignment inside main()
}
Some Points to remember
1. You can change the value and behaviour of these pointers on runtime. That means, you can point it to other member function or member variable.
2. To have pointer to data member and member functions you need to make them public.
Overview of Inheritance
Inheritance is the capability of one class to acquire properties and characteristics from another class. The class whose properties are inherited by other class is called the Parent or Base or Super class. And, the class which inherits properties of other class is called Child or Derived or Sub class.
Inheritance makes the code reusable. When we inherit an existing class, all its methods and fields become available in the new class, hence code is reused.
NOTE : All members of a class except Private, are inherited
Purpose of Inheritance
1. Code Reusability
2. Method Overriding (Hence, Runtime Polymorphism.)
3. Use of Virtual Keyword
Basic Syntax of Inheritance
class Subclass_name : access_mode Superclass_name
While defining a subclass like this, the super class must be already defined or atleast declared before the subclass declaration.
Access Mode is used to specify, the mode in which the properties of superclass will be inherited into subclass, public, privtate or protected.
Example of Inheritance
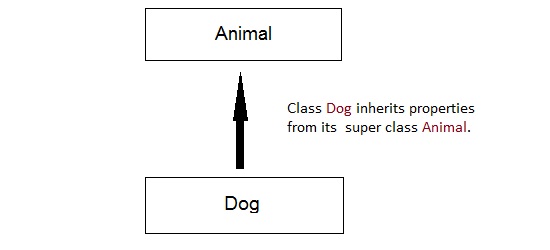
class Animal
{ public:
int legs = 4;
};
class Dog : public Animal
{ public:
int tail = 1;
};
int main()
{
Dog d;
cout << d.legs;
cout << d.tail;
}
Output : 4 1
Inheritance Visibility Mode
Depending on Access modifier used while inheritance, the availability of class members of Super class in the sub class changes. It can either be private, protected or public.
1) Public Inheritance
This is the most used inheritance mode. In this the protected member of super class becomes protected members of sub class and public becomes public.
class Subclass : public Superclass
2) Private Inheritance
In private mode, the protected and public members of super class become private members of derived class.
class Subclass : Superclass // By default its private inheritance
3) Protected Inheritance
In protected mode, the public and protected members of Super class becomes protected members of Sub class.
class subclass : protected Superclass
Table showing all the Visibility Modes
|
Base class |
Derived Class |
||
|
Public Mode |
Private Mode |
Protected Mode |
|
|
Private |
Not Inherited |
Not Inherited |
Not Inherited |
|
Protected |
Protected |
Private |
Protected |
|
Public |
Public |
Private |
Protected |
Types of Inheritance
In C++, we have 5 different types of Inheritance. Namely,
1. Single Inheritance
2. Multiple Inheritance
3. Hierarchical Inheritance
4. Multilevel Inheritance
5. Hybrid Inheritance (also known as Virtual Inheritance)
Single Inheritance
In this type of inheritance one derived class inherits from only one base class. It is the most simplest form of Inheritance.
Multiple Inheritance
In this type of inheritance a single derived class may inherit from two or more than two base classes.
Hierarchical Inheritance
In this type of inheritance, multiple derived classes inherits from a single base class.
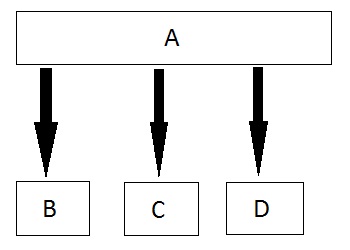
Multilevel Inheritance
In this type of inheritance the derived class inherits from a class, which in turn inherits from some other class. The Super class for one, is sub class for the other.
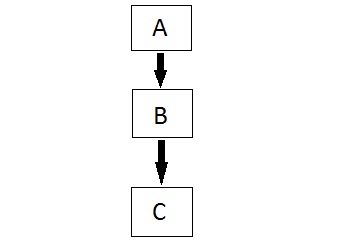
Hybrid (Virtual) Inheritance
Hybrid Inheritance is combination of Hierarchical and Mutilevel Inheritance.
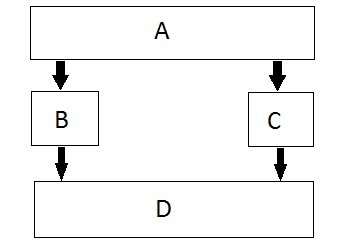
Order of Constructor Call
Base class constructors are always called in the derived class constructors. Whenever you create derived class object, first the base class default constructor is executed and then the derived class's constructor finishes execution.
Points to Remember
1. Whether derived class's default constructor is called or parameterised is called, base class's default constructor is always called inside them.
2. To call base class's parameterised constructor inside derived class's parameterised constructo, we must mention it explicitly while declaring derived class's parameterized constructor.
Base class Default Constructor in Derived class Constructors
class Base
{ int x;
public:
Base() { cout << "Base default constructor"; }
};
class Derived : public Base
{ int y;
public:
Derived() { cout << "Derived default constructor"; }
Derived(int i) { cout << "Derived parameterized constructor"; }
};
int main()
{
Base b;
Derived d1;
Derived d2(10);
}
You will see in the above example that with both the object creation of the Derived class, Base class's default constructor is called.
Base class Parameterized Constructor in Derived class Constructor
We can explicitly mention to call the Base class's parameterized constructor when Derived class's parameterized constructor is called.
class Base
{ int x;
public:
Base(int i)
{ x = i;
cout << "Base Parameterized Constructor";
}
};
class Derived : public Base
{ int y;
public:
Derived(int j) : Base(j)
{ y = j;
cout << "Derived Parameterized Constructor";
}
};
int main()
{
Derived d(10) ;
cout << d.x ; // Output will be 10
cout << d.y ; // Output will be 10
}
Why is Base class Constructor called inside Derived class ?
Constructors have a special job of initializing the object properly. A Derived class constructor has access only to its own class members, but a Derived class object also have inherited property of Base class, and only base class constructor can properly initialize base class members. Hence all the constructors are called, else object wouldn't be constructed properly.
Constructor call in Multiple Inheritance
Its almost the same, all the Base class's constructors are called inside derived class's constructor, in the same order in which they are inherited.
class A : public B, public C ;
In this case, first class B constructor will be executed, then class C constructor and then class A constructor.
Upcasting in C++
Upcasting is using the Super class's reference or pointer to refer to a Sub class's object. Or we can say that, the act of converting a Sub class's reference or pointer into its Super class's reference or pointer is called Upcasting.
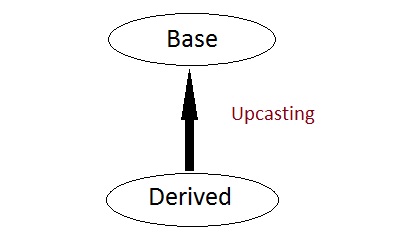
class Super
{ int x;
public:
void funBase() { cout << "Super function"; }
};
class Sub : public Super
{ int y;
};
int main()
{
Super* ptr; // Super class pointer
Sub obj;
ptr = &obj;
Super &ref; // Super class's reference
ref=obj;
}
The opposite of Upcasting is Downcasting, in which we convert Super class's reference or pointer into derived class's reference or pointer. We will study more about Downcasting later
Functions that are never Inherited
- Constructors and Destructors are never inherited and hence never overrides.
- Also, assignment operator = is never inherited. It can be overloaded but can't be inherited by sub class.
Inheritance and Static Functions
1. They are inherited into the derived class.
2. If you redefine a static member function in derived class, all the other overloaded functions in base class are hidden.
3. Static Member functions can never be virtual. We will study about Virtual in coming topics.
Hybrid Inheritance and Virtual Class
In Multiple Inheritance, the derived class inherits from more than one base class. Hence, in Multiple Inheritance there are a lot chances of ambiguity.
class A
{ void show(); };
class B:public A {};
class C:public A {};
class D:public B, public C {};
int main()
{
D obj;
obj.show();
}
In this case both class B and C inherits function show() from class A. Hence class D has two inherited copies of function show(). In main() function when we call function show(), then ambiguity arises, because compiler doesn't know which show() function to call. Hence we use Virtual keyword while inheriting class.
class B : virtual public A {};
class C : virtual public A {};
class D : public B, public C {};
Now by adding virtual keyword, we tell compiler to call any one out of the two show() funtions.
Hybrid Inheritance and Constructor call
As we all know that whenever a derived class object is instantiated, the base class constructor is always called. But in case of Hybrid Inheritance, as discussed in above example, if we create an instance of class D, then following constructors will be called :
- before class D's constructor, constructors of its super classes will be called, hence constructors of class B, class C and class A will be called.
- when constructors of class B and class C are called, they will again make a call to their super class's constructor.
This will result in multiple calls to the constructor of class A, which is undesirable. As there is a single instance of virtual base class which is shared by multiple classes that inherit from it, hence the constructor of the base class is only called once by the constructor of concrete class, which in our case is class D.
If there is any call for initializing the constructor of class A in class B or class C, while creating object of class D, all such calls will be skipped.
Polymorphism in C++
Polymorphism means having multiple forms of one thing. In inheritance, polymorphism is done, by method overriding, when both super and sub class have member function with same declaration but different definition.
Function Overriding
If we inherit a class into the derived class and provide a definition for one of the base class's function again inside the derived class, then that function is said to be overridden, and this mechanism is called Function Overriding
Requirements for Overriding
1. Inheritance should be there. Function overriding cannot be done within a class. For this we require a derived class and a base class.
2. Function that is redefined must have exactly the same declaration in both base and derived class, that means same name, same return type and same parameter list.
Example of Function Overriding
class Base
{
public:
void show()
{
cout << "Base class";
}
};
class Derived:public Base
{
public:
void show()
{
cout << "Derived Class";
}
}
In this example, function show() is overridden in the derived class. Now let us study how these overridden functions are called in main() function.
Function Call Binding with class Objects
Connecting the function call to the function body is called Binding. When it is done before the program is run, its called Early Binding or Static Binding or Compile-time Binding.
class Base
{
public:
void shaow()
{
cout << "Base class\t";
}
};
class Derived:public Base
{
public:
void show()
{
cout << "Derived Class";
}
}
int mian()
{
Base b; //Base class object
Derived d; //Derived class object
b.show(); //Early Binding Ocuurs
d.show();
}
Output : Base class Derived class
In the above example, we are calling the overrided function using Base class and Derived class object. Base class object will call base version of the function and derived class's object will call the derived version of the function.
Function Call Binding using Base class Pointer
But when we use a Base class's pointer or reference to hold Derived class's object, then Function call Binding gives some unexpected results.
class Base
{
public:
void shaow()
{
cout << "Base class";
}
};
class Derived:public Base
{
public:
void show()
{
cout << "Derived Class";
}
}
int main()
{
Base* b; //Base class pointer
Derived d; //Derived class object
b = &d;
b->show(); //Early Binding Ocuurs
}
Output : Base class
In the above example, although, the object is of Derived class, still Base class's method is called. This happens due to Early Binding.
Compiler on seeing Base class's pointer, set call to Base class's show() function, without knowing the actual object type.
Virtual Functions
Virtual Function is a function in base class, which is overrided in the derived class, and which tells the compiler to perform Late Binding on this function.
Virtual Keyword is used to make a member function of the base class Virtual.
Late Binding
In Late Binding function call is resolved at runtime. Hence, now compiler determines the type of object at runtime, and then binds the function call. Late Binding is also called Dynamic Binding or Runtime Binding.
Problem without Virtual Keyword
class Base
{
public:
void show()
{
cout << "Base class";
}
};
class Derived:public Base
{
public:
void show()
{
cout << "Derived Class";
}
}
int main()
{
Base* b; //Base class pointer
Derived d; //Derived class object
b = &d;
b->show(); //Early Binding Ocuurs
}
Output : Base class
When we use Base class's pointer to hold Derived class's object, base class pointer or reference will always call the base version of the function
Using Virtual Keyword
We can make base class's methods virtual by using virtual keyword while declaring them. Virtual keyword will lead to Late Binding of that method.
class Base
{
public:
virtual void show()
{
cout << "Base class";
}
};
class Derived:public Base
{
public:
void show()
{
cout << "Derived Class";
}
}
int main()
{
Base* b; //Base class pointer
Derived d; //Derived class object
b = &d;
b->show(); //Late Binding Ocuurs
}
Output : Derived class
On using Virtual keyword with Base class's function, Late Binding takes place and the derived version of function will be called, because base class pointer pointes to Derived class object.
Using Virtual Keyword and Accessing Private Method of Derived class
We can call private function of derived class from the base class pointer with the help of virtual keyword. Compiler checks for access specifier only at compile time. So at run time when late binding occurs it does not check whether we are calling the private function or public function.
#include
using namespace std;
class A
{
public:
virtual void show()
{
cout << "Base class\n";
}
};
class B: public A
{
private:
virtual void show()
{
cout << "Derived class\n";
}
};
int main()
{
A *a;
B b;
a = &b;
a -> show();
}
Output : Derived class
Mechanism of Late Binding
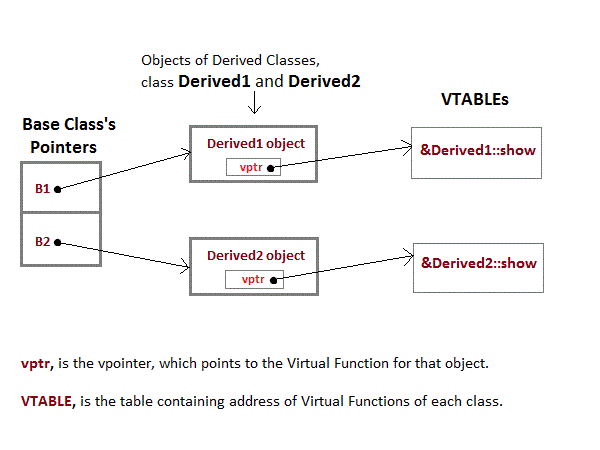
To accomplich late binding, Compiler creates VTABLEs, for each class with virtual function. The address of virtual functions is inserted into these tables. Whenever an object of such class is created the compiler secretly inserts a pointer called vpointer, pointing to VTABLE for that object. Hence when function is called, compiler is able to resovle the call by binding the correct function using the vpointer.
Important Points to Remember
1. Only the Base class Method's declaration needs the Virtual Keyword, not the definition.
2. If a function is declared as virtual in the base class, it will be virtual in all its derived classes.
3. The address of the virtual Function is placed in the VTABLE and the copiler uses VPTR(vpointer) to point to the Virtual Function.
Abstract Class in C++
Abstract Class is a class which contains atleast one Pure Virtual function in it. Abstract classes are used to provide an Interface for its sub classes. Classes inheriting an Abstract Class must provide definition to the pure virtual function, otherwise they will also become abstract class.
Characteristics of Abstract Class
1. Abstract class cannot be instantiated, but pointers and refrences of Abstract class type can be created.
2. Abstract class can have normal functions and variables along with a pure virtual function.
3. Abstract classes are mainly used for Upcasting, so that its derived classes can use its interface.
4. Classes inheriting an Abstract Class must implement all pure virtual functions, or else they will become Abstract too.
Pure Virtual Functions
Pure virtual Functions are virtual functions with no definition. They start with virtual keyword and ends with= 0. Here is the syntax for a pure virtual function,
virtual void f() = 0;
Example of Abstract Class
class Base //Abstract base class
{
public:
virtual void show() = 0;//Pure Virtual Function
};
classDerived:public Base
{
public:
void show()
{ cout<< "Implementation of Virtual Function in Derived class"; }
};
int main()
{
Base obj; //Compile Time Error
Base *b;
Derived d;
b = &d;
b->show();
}
Output : Implementation of Virtual Function in Derived class
In the above example Base class is abstract, with pure virtual show() function, hence we cannot create object of base class.
Why can't we create Object of Abstract Class ?
When we create a pure virtual function in Abstract class, we reserve a slot for a function in the VTABLE(studied in last topic), but doesn't put any address in that slot. Hence the VTABLE will be incomplete.
As the VTABLE for Abstract class is incomplete, hence the compiler will not let the creation of object for such class and will display an errror message whenever you try to do so.
Pure Virtual definitions
- Pure Virtual functions can be given a small definition in the Abstract class, which you want all the derived classes to have. Still you cannot create object of Abstract class.
- Also, the Pure Virtual function must be defined outside the class definition. If you will define it inside the class definition, complier will give an error. Inline pure virtual definition is Illegal.
class Base //Abstract base class
{
public:
virtual void show() = 0;//Pure Virtual Function
};
void Base :: show() //Pure Virtual definition
{
cout<< "Pure Virtual definition\n";
}
classDerived:public Base
{
public:
voidshow()
{ cout<< "Implementation of Virtual Function in Derived class"; }
};
int main()
{
Base *b;
Derived d;
b = &d;
b->show();
}
Output :
Pure Virtual definition
Implementation of Virtual Function in Derived class
Virtual Destructors in C++
Destructors in the Base class can be Virtual. Whenever Upcasting is done, Destructors of the Base class must be made virtual for proper destrucstion of the object when the program exits.
NOTE : Constructors are never Virtual, only Destructors can be Virtual.
Upcasting without Virtual Destructor
Lets first see what happens when we do not have a virtual Base class destructor.
class Base
{
public:
~Base() {cout << "Base Destructor\t"; }
};
class Derived:public Base
{
public:
~Derived() { cout<< "Derived Destructor"; }
};
int main()
{
Base* b = new Derived; //Upcasting
delete b;
}
Output : Base Destructor
In the above example, delete b will only call the Base class destructor, which is undesirable because, then the object of Derived class remains undestructed, because its destructor is never called. Which results in memory leak.
Upcasting with Virtual Destructor
Now lets see. what happens when we have Virtual destructor in the base class.
class Base
{
public:
virtual ~Base() {cout << "Base Destructor\t"; }
};
class Derived:public Base
{
public:
~Derived() { cout<< "Derived Destructor"; }
};
int main()
{
Base* b = new Derived; //Upcasting
delete b;
}
Output :
Derived Destructor
Base Destructor
When we have Virtual destructor inside the base class, then first Derived class's destructor is called and then Base class's destructor is called, which is the desired behaviour.
Pure Virtual Destructors
- Pure Virtual Destructors are legal in C++. Also, pure virtual Destructors must be defined, which is against the pure virtual behaviour.
- The only difference between Virtual and Pure Virtual Destructor is, that pure virtual destructor will make its Base class Abstract, hence you cannot create object of that class.
- There is no requirement of implementing pure virtual destructors in the derived classes.
class Base
{
public:
virtual ~Base() = 0; //Pure Virtual Destructor
};
Base::~Base() { cout << "Base Destructor"; } //Definition of Pure Virtual Destructor
class Derived:public Base
{
public:
~Derived() { cout<< "Derived Destructor"; }
};
Operator Overloading in C++
Operator overloading is an important concept in C++. It is a type of polymorphism in which an operator is overloaded to give user defined meaning to it. Overloaded operator is used to perform operation on user-defined data type. For example '+' operator can be overloaded to perform addition on various data types, like for Integer, String(concatenation) etc.

Almost any operator can be overloaded in C++. However there are few operator which can not be overloaded.Operator that are not overloaded are follows
- scope operator - ::
- sizeof
- member selector - .
- member pointer selector - *
- ternary operator - ?:
Operator Overloading Syntax
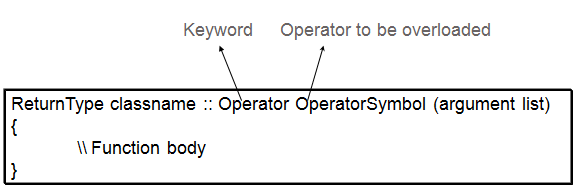
Implementing Operator Overloading
Operator overloading can be done by implementing a function which can be:
1. Member Function
2. Non-Member Function
3. Friend Function
Operator overloading function can be a member function if the Left operand is an Object of that class, but if the Left operand is different, then Operator overloading function must be a non-member function.
Operator overloading function can be made friend function if it needs access to the private and protected members of class.
Restrictions on Operator Overloading
Following are some restrictions to be kept in mind while implementing operator overloading.
1. Precedence and Associativity of an operator cannot be changed.
2. Arity (numbers of Operands) cannot be changed. Unary operator remains unary, binary remains binary etc.
3. No new operators can be created, only existing operators can be overloaded.
4. Cannot redefine the meaning of a procedure. You cannot change how integers are added.
Operator Overloading Examples
Almost all the operators can be overloaded in infinite different ways. Following are some examples to learn more about operator overloading. All the examples are closely connected.
Overloading Arithmetic Operator
Arithmetic operator are most commonly used operator in C++. Almost all arithmetic operator can be overloaded to perform arithmetic operation on user-defined data type. In the below example we have overridden the + operator, to add to Time(hh:mm:ss) objects.
Example: overloading '+' Operator to add two time object
#include< iostream.h>
#include< conio.h>
class time
{
int h,m,s;
public:
time()
{
h=0, m=0; s=0;
}
void getTime();
void show()
{
cout<< h<< ":"<< m<< ":"<< s;
}
time operator+(time);//overloading '+' operator
};
time time::operator+(time t1) //operator function
{
time t;
int a,b;
a=s+t1.s;
t.s=a%60;
b=(a/60)+m+t1.m;
t.m=b%60;
t.h=(b/60)+h+t1.h;
t.h=t.h%12;
return t;
}
void time::getTime()
{
cout<<"\n Enter the hour(0-11) ";
cin>>h;
cout<<"\n Enter the minute(0-59) ";
cin>>m;
cout<<"\n Enter the second(0-59) ";
cin>>s;
}
void main()
{
clrscr();
time t1,t2,t3;
cout<<"\n Enter the first time ";
t1.getTime();
cout<<"\n Enter the second time ";
t2.getTime();
t3=t1+t2; //adding of two time object using '+' operator
cout<<"\n First time ";
t1.show();
cout<<"\n Second time ";
t2.show();
cout<<"\n Sum of times ";
t3.show();
getch();
}
Overloading I/O operator
- Overloaded to perform input/output for user defined datatypes.
- Left Operand will be of types ostream& and istream&
- Function overloading this operator must be a Non-Member function because left operand is not an Object of the class.
- It must be a friend function to access private data members.
You have seen above that << operator is overloaded with ostream class object cout to print primitive type value output to the screen. Similarly you can overload << operator in your class to print user-defined type to screen. For example we will overload << in time class to display time object using cout.
time t1(3,15,48);
cout << t1;
NOTE: When the operator does not modify its operands, the best way to overload the operator is via friend function.
Example: overloading '<<' Operator to print time object
#include< iostream.h>
#include< conio.h>
class time
{
int hr,min,sec;
public:
time()
{
hr=0, min=0; sec=0;
}
time(int h,int m, int s)
{
hr=h, min=m; sec=s;
}
friend ostream& operator << (ostream &out, time &tm); //overloading '<<' operator
};
ostream& operator<< (ostream &out, time &tm) //operator function
{
out << "Time is " << tm.hr << "hour : " << tm.min << "min : " << tm.sec << "sec";
return out;
}
void main()
{
time tm(3,15,45);
cout << tm;
}
Output
Time is 3 hour : 15 min : 45 sec
Overloading Relational operator
You can also overload Relational operator like == , != , >= , <= etc. to compare two user-defined object.
Example
class time
{
int hr,min,sec;
public:
time()
{
hr=0, min=0; sec=0;
}
time(int h,int m, int s)
{
hr=h, min=m; sec=s;
}
friend bool operator==(time &t1, time &t2);//overloading '==' operator
};
bool operator== (time &t1, time &t2) //operator function
{
return ( t1.hr == t2.hr &&
t1.min == t2.min &&
t1.sec == t2.sec );
}
Copy constructor Vs. Assignment operator
Assignment operator is used to copy the values from one object to another already existing object. For example
time tm(3,15,45); //tm object created and initialized
time t1; //t1 object created
t1 = tm; //initializing t1 using tm
Copy constructor is a special constructor that initializes a new object from an existing object.
time tm(3,15,45); //tm object created and initialized
time t1(tm); //t1 object created and initialized using tm object




